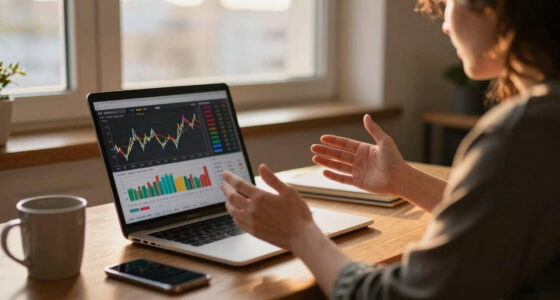
TL;DR
A May 2026 Google whitepaper by Addy Osmani, Shubham Saboo and Sokratis Kartakis argues that AI-assisted software development is moving from code writing to intent setting. The paper says model choice is only a small part of agent performance, while verification, tools, context and engineering controls determine whether AI code is safe for production.
A new Google whitepaper, The New SDLC With Vibe Coding, argues that the main shift in software engineering is not a new programming language or framework, but a move from writing code directly to expressing intent and verifying machine-generated output, a change that could reshape how teams budget, test and govern AI-assisted development.
The paper, written by Addy Osmani, Shubham Saboo and Sokratis Kartakis, reports that 85% of professional developers regularly use AI coding agents, 51% use them daily, and about 41% of new code is AI-generated. Those figures are presented by the authors as evidence that AI coding tools have moved into routine engineering work.
The central claim is that the model itself accounts for only a small share of agent behavior. The paper describes an agent as a combination of a model and a surrounding harness: prompts, tools, context rules, sandboxes, hooks, sub-agents, observability and CI checks.
The source material attributes several performance gains to changes outside the model, including a Terminal Bench 2.0 result in which an agent reportedly moved from outside the top 30 to the top five after harness changes using the same model. A separate LangChain experiment is cited as improving an agent score by 13.7 points through prompt, tool and middleware changes.
The model is only 10%
A Google whitepaper argues software’s biggest shift is from writing code to expressing intent. Its sharpest claim: the model you obsess over is the smallest part of the system — the scaffolding around it does the real work.
The clearest map yet of how serious AI development works — and mostly tool-agnostic. But it’s a Google funnel: the concepts are neutral, the on-ramps point to Gemini, Jules & the ADK. If the harness is 90% and it’s yours, your moat and your costs both live there — so own your scaffolding, route across models, and remember: AI amplifies whatever engineering culture it lands in.
Verification Becomes The Cost Center
The paper matters because it reframes the business risk of AI coding. If generated code is already widespread, the harder problem is no longer whether AI can produce software, but whether teams can prove that output is correct, maintainable and secure enough to ship.
Google’s authors draw a line between casual “vibe coding” and what they call agentic engineering. In their framing, quick prompts and surface-level checks may be acceptable for prototypes or disposable scripts, while production systems need formal specifications, automated tests, evals, CI gates and human review of architecture.
The cost argument is also direct. The paper casts casual AI coding as low upfront cost but high long-term operating cost, because repeated fix loops, unclear code ownership, maintenance burden and security remediation can add up. Agentic engineering, by contrast, requires more early investment in specs, evals and context design, but may reduce rework if those systems raise first-pass success.
AI coding tools with verification features
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
From Vibes To Engineering Controls
The term “vibe coding” was popularized by Andrej Karpathy in 2025 and has since been used loosely for many forms of AI-assisted coding. The Google paper narrows that meaning by placing workflows on a spectrum rather than treating all AI coding as the same practice.
At one end is casual prompting: a developer asks for code, runs it, pastes back errors and accepts output when it appears to work. At the other end is a managed workflow in which agents operate inside written requirements, test suites, evaluation rubrics, restricted tools and review gates.
The paper’s more practical contribution is its claim that tests and evals serve different roles. Tests check deterministic behavior, such as whether a known input produces the expected output. Evals are meant to judge less predictable work, such as whether an agent chose suitable tools or met a quality bar.
“generation is solved; verification, judgment, and direction are the new craft”
— Osmani, Saboo and Kartakis, in Google’s whitepaper

Electromagnetic Inductance Tester 2 Pcs, in-Circuit Inductor Tester, Induction Detector for Motherboard Repair, in Circuit PCB Board Coil Testers Tool
【Fast Detection】Designed for quick troubleshooting of inductors on PCB boards with high sensitivity contact detection, helping locate potential…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Benchmarks Leave Open Questions
Several points remain unsettled. The paper’s reported adoption figures and benchmark results are attributed to the authors and cited sources, but the source material does not provide enough detail to independently verify how broadly those results apply across companies, languages, codebases or regulated environments.
It is also unclear how durable the “10% model, 90% harness” split is. The figure is presented as a rough framing, not a universal measurement. Different teams may see different results depending on codebase maturity, test quality, tooling access, security requirements and the skill of engineers designing agent workflows.
The source material also notes a commercial angle: while the concepts are described as tool-agnostic, the Google paper points readers toward Google products such as Gemini, Jules and the Agent Development Kit. Readers should separate the engineering model from vendor-specific recommendations.

Production-Ready AI Agents: The Senior Engineer's Complete Guide to Building, Debugging, Evaluating, and Scaling LLM Agent Systems in Production Environments
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Teams Rework AI Guardrails
The next stage is likely to be practical rather than theoretical. Engineering leaders will need to decide where AI agents can act, what tools they may use, which tasks require human approval, and which tests or evals must pass before generated code reaches production.
For readers managing software teams, the paper points to a near-term checklist: improve specifications, build stronger test coverage, add evals for agent behavior, route simple work to cheaper models when appropriate, and track failures by harness design rather than blaming the model by default.

GitHub Copilot for Autonomous Software Engineering: Harness the Power of AI to Optimize Code, Automate Tasks, and Supercharge Your Development Process
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
What is the actual news development?
Google published a May 2026 whitepaper arguing that AI-assisted software development is moving from manual coding toward intent-driven workflows backed by tests, evals and agent controls.
Is this breaking news or analysis?
This is an analysis piece based on a recent Google whitepaper and a source analysis from Thorsten Meyer AI, not a breaking incident or product launch.
What is confirmed?
The confirmed development is the publication and content of the Google whitepaper as described in the supplied source material. Adoption percentages, benchmark outcomes and cost comparisons are claims attributed to the paper and cited experiments.
Why does this matter to developers?
It suggests that model selection alone may not decide whether AI coding works well. Teams may need stronger specs, tests, evals, security checks and observability to make generated code dependable.
What remains uncertain?
It is still unclear how broadly the paper’s ratios and benchmark lessons apply across different organizations, legacy systems and high-risk software environments.
Source: Thorsten Meyer AI